Application of a niche-based model for forest cover classification
Forest@ - Journal of Silviculture and Forest Ecology, Volume 9, Pages 75-88 (2012)
doi: https://doi.org/10.3832/efor0689-009
Published: May 07, 2012 - Copyright © 2012 SISEF
Research Articles
Abstract
In recent years, a surge of interest in biodiversity conservation have led to the development of new approaches to facilitate ecologically-based conservation policies and management plans. In particular, image classification and predictive distribution modeling applied to forest habitats, constitute a crucial issue as forests constitute the most widespread vegetation type and play a key role for ecosystem functioning. Then, the general purpose of this study is to develop a framework that in the absence of large amounts of field data for large areas may allow to select the most appropriate classification. In some cases, a hard division of classes is required, especially as support to environmental policies; despite this it is necessary to take into account problems which derive from a crisp view of ecological entities being mapped, since habitats are expected to be structurally complex and continuously vary within a landscape. In this paper, a niche model (MaxEnt), generally used to estimate species/habitat distribution, has been applied to classify forest cover in a complex Mediterranean area and to estimate the probability distribution of four forest types, producing continuous maps of forest cover. The use of the obtained models as validation of model for crisp classifications, highlighted that crisp classification, which is being continuously used in landscape research and planning, is not free from drawbacks as it is showing a high degree of inner variability. The modeling approach followed by this study, taking into account the uncertainty proper of the natural ecosystems and the use of environmental variables in land cover classification, may represent an useful approach to making more efficient and effective field inventories and to developing effective forest conservation policies.
Keywords
Crisp classification, Ecological niche, Forest cover map, MaxEnt, Remote sensing
Introduzione
Negli ultimi anni, un crescente interesse nei confronti della biodiversità e della sua conservazione ha portato allo sviluppo di nuovi metodi per la classificazione della superficie terrestre ([22], [51]). La classificazione delle immagini satellitari e lo sviluppo di modelli predittivi della distribuzione delle specie o degli habitat sono approcci classici che consentono di sviluppare efficaci politiche di conservazione ([53], [15]).
Lo sviluppo di modelli per la classificazione degli habitat forestali rappresenta un importante supporto alla pianificazione, in quanto le foreste costituiscono la tipologia di habitat maggiormente diffusa sulla superficie terrestre e occupano un ruolo cruciale nella funzionalità degli ecosistemi ([43], [59], [39], [46]). Inoltre, grazie ad una elevata variabilità spaziale e strutturale, gli ecosistemi forestali sono associati ad un alto grado di biodiversità e complessità in termini di specie, genotipi e processi ecologici ([31], [27]).
L’efficienza nella gestione e la conservazione delle risorse forestali potrebbe essere migliorata se fossero disponibili mappe tematiche accurate, realizzate attraverso l’uso integrato di dati di campo e da telerilevamento ([67], [11], [54], [36]).
Tradizionalmente le cartografie tematiche presenti all’interno di strumenti di pianificazione del territorio sono generalmente realizzate tramite tecniche di classificazione discreta o crisp ([17], [52]). Tali tecniche prevedono l’attribuzione di un poligono o di un pixel ad una singola classe all’interno del sistema di nomenclatura scelto, attraverso quindi una condizione di appartenenza di tipo booleano {0/1}. La diretta conseguenza di tale sistema di attribuzione è l’impossibilità intrinseca di identificare tipologie caratterizzate da un certo grado di eterogeneità, costringendo la struttura spazialmente continua ed organizzata gerarchicamente dei paesaggi terrestri in un numero finito di classi non sovrapponibili ([51]).
Un metodo alternativo per ottimizzare i metodi tradizionali di rappresentazione dell’informazione geografica è quello di utilizzare classificatori di tipo soft, ovvero in grado di identificare il grado di variabilità interna all’entità da classificare (pixel o poligono) sulla base di una funzione di appartenenza di tipo continuo ([18], [66]). In questo modo, il processo di attribuzione ad una classe di appartenenza non sarà più rigido e limitato alla condizione di appartenenza di tipo booleano {0/1}, ma sarà graduale, cioè variabile da 0 (grado di appartenenza nullo) a 1 (grado di appartenenza certo).
La natura probabilistica di tale tipo di classificatori permette di includere i modelli di distribuzione di specie o habitat tra le tecniche utilizzabili per mappare la distribuzione di determinate classi di copertura del suolo ([24], [13]). Tale applicazione si basa sulla quantificazione delle relazioni esistenti tra la distribuzione di un pool di specie caratteristico di ogni tipologia vegetazionale indagata e le variabili ambientali che ne possono influenzare la distribuzione ([32], [35]). I dati necessari per realizzare tali modelli consistono in un set di coordinate geografiche, che identificano il luogo dove le specie sono state raccolte, e i valori delle variabili predittrici, come temperatura media, piovosità media, altitudine, misurate o stimate su tutta la regione di interesse. Solitamente sono costruiti come semplici modelli empirici ([25]) e una volta messi a punto permettono di generare mappe che descrivono la distribuzione potenziale di un determinato habitat, ovvero l’insieme delle condizioni ambientali che assicurano alle specie costituenti l’habitat di soddisfare i propri requisiti vitali minimi ([4], [5], [7]).
Da un punto di vista conoscitivo, l’incertezza introdotta dai classificatori di tipo soft e dai modelli probabilistici di distribuzione permette una più accurata osservazione dei pattern di distribuzione e della complessità propria dei sistemi naturali ([17], [51], [3]).
L’obiettivo generale di questo studio è di proporre un approccio alternativo alla classificazione delle superfici forestali, basato sull’uso integrato di dati di campo e analisi GIS nello sviluppo di modelli di distribuzione di alcune tipologie forestali. In particolare tramite questo lavoro è stata valutata la possibilità di utilizzo di un modello basato sul concetto di nicchia ecologico nell’ambito della classificazione del territorio, utilizzando un sistema di nomenclatura standardizzato come il Corine Land Cover per la scelta delle tipologie forestali da includere nell’analisi. Gli scopi specifici di questo studio sono: (i) testare un modello basato sulla massima entropia (MaxEnt) per classificare la copertura di quattro tipologie forestali in ambiente mediterraneo e per stimare la loro probabilità di distribuzione; (ii) valutare l’utilizzo di modelli di tipo MaxEnt allo scopo di stimare l’incertezza associata alla classificazione in classi discrete o crisp e al fine di valutare la quantità di variabilità persa utilizzando insiemi discreti per l’identificazione delle tipologie forestali.
Materiali e metodi
Area di studio
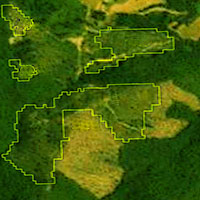
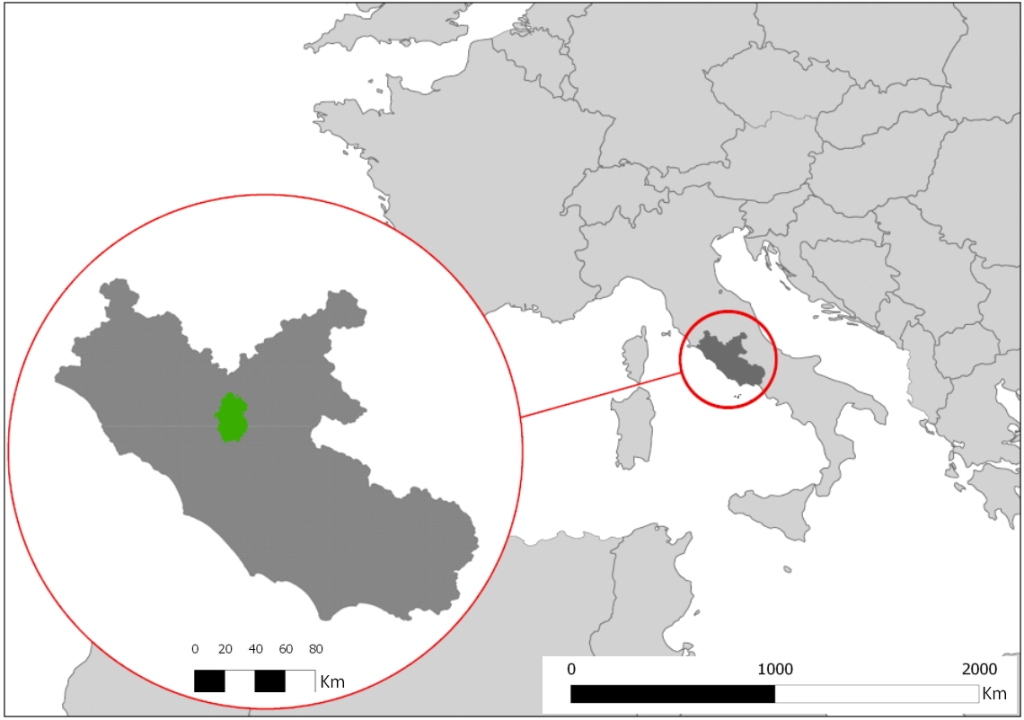
L’area di studio è rappresentata da un tipico paesaggio mediterraneo e copre circa 303 km2 collocandosi nella porzione nord della provincia di Roma (tra 42° 05’ e 42° 30’ Latitudine Nord e 12° 43’ e 12° 64’ Longitudine Est, UTM WGS84 - Fig. 1). L’area è dominata dal monte Soratte (693 metri), un rilievo carbonatico che si erge dalle basse colline vulcaniche circostanti (altezza media 200 metri). La piana alluvionale del fiume Tevere (altezza media 36 metri) occupa la parte Est di quest’area, ed è costituita da una pianura alluvionale ampia, scavata durante l’ultimo periodo glaciale e successivamente riempita da sedimenti di alluvioni recenti ([63]). Da un punto di vista orografico l’area di studio può essere divisa in 3 zone distinte: (i) la valle del Tevere, caratterizzata dalla presenza di corsi d’acqua, aree umide con vegetazione igrofila e sub-igrofila del piano alluvionale; (ii) la zona collinare, caratterizzata da terreni coltivati di piccole dimensioni intervallati da strette zone boschive (specie caducifoglie con prevalenza di Quercus pubescens e Q. cerris) e siepi, pseudo-steppe di graminacee e piante annuali; (iii) l’area del Monte Soratte, dove sono presenti praterie calcaree, foreste caducifoglie e vegetazione a sclerofille (boschi misti a prevalenza di Quercus ilex, arbusteti e boschi con prevalenza di Q. ilex, Pistacia lentiscus, Phyllirea latifolia e Rhamnus alaternus - [47]).
Fig. 1 - Area di studio.
Modello di distribuzione delle tipologie forestali
Il rilievo a terra è stato effettuato tramite il campionamento di 60 punti (15 punti per ogni tipologia forestale presente nell’area di studio) selezionati in modo casuale esclusivamente all’interno di aree forestali. Una volta localizzato con un GPS ad alta precisione, ogni punto è stato classificato in base alla specie arborea dominante in un intorno di 30 metri e raggruppato nelle seguenti tipologie forestali, individuate sulla base dello schema di classificazione Corine Land Cover al IV livello ([6]): (i) “Boschi di leccio” (Quercus ilex); (ii) “Boschi misti di querce caducifoglie” (Q. pubescens, Q. cerris); (iii) “Boschi misti di caducifoglie” (Acer campestre, A. monspessulanum, Ostrya carpinifolia, Fraxinus ornus; (iv) “Boschi ripariali” (Populus spp., Salix spp.).
Successivamente, 6 bande Landsat ETM+ (colonna 191, riga 031, data di acquisizione Luglio 2005; risoluzione spaziale 30 m, bande 1-5 e 7) e undici variabili geomorfologiche (altitudine, esposizione, pendenza, radiazione solare), pedologiche (suolo) e climatiche (temperatura minima annua, temperatura massima annua, temperatura minima media invernale, temperatura media massima estiva, piovosità media annuale, umidità ), sono state considerate come potenziali predittori della distribuzione delle tipologie forestali individuate.
Al fine di ottenere le variabili geomorfologiche è stato utilizzato un modello digitale del terreno (DEM) dell’area di studio, mentre le variabili climatiche (2004-2011) sono state ricavate da interpolazione spaziale (Inverse Distance Weighting) dei valori rilevati da 10 stazioni climatiche (Bracciano - Prato Pianciano, Cantalupo - S. Francesco, Civitella S. Paolo - Le Cese, Corchiano - Pantalone, Fara in Sabina - Canneto, Fara in Sabina - S. Andrea, Monterotondo - Grotta Marozza, Montopoli in Sabina - Villa Caprola, Montopoli in Sabina - Colle Arcone, Roma - via Lanciani) dell’Agenzia Regionale per lo sviluppo e l’innovazione in Agricoltura (ARSIAL). I raster relativi alle variabili geomorfologiche e climatiche sono stati ricampionati a 30 m per uniformare la risoluzione dei dati utilizzati. La carta pedologica è stata estratta dal database “GIS Natura. Il GIS delle conoscenze naturalistiche in Italia” fornito dal Ministero dell’Ambiente e Tutela del Territorio, con una unità minima mappabile, relativa all’area di studio, di 0.5 ha. Tutte le operazione di elaborazione immagini dei dataset cartografici sono state effettuate tramite i software GIS Grass ([23]) e QGIS ([48]).
Al fine di escludere le coppie di variabili correlate è stata effettuata un’analisi di correlazione, utilizzando il software R ([49]).
Per lo sviluppo dei modelli di distribuzione degli habitat forestali è stato utilizzato il software MaxEnt (Maximum Entropy Modeling - [44], [45], [14]), che implementa un algoritmo di modellizzazione indicato in letteratura come il migliore approccio tra i diversi tipi di modelli di distribuzione esistenti ([28], [40]). MaxEnt utilizza un metodo di apprendimento automatico per la stima della distribuzione di una specie o di un habitat basato sulla massima entropia. Tale metodo valuta l’idoneità di ogni pixel in funzione delle variabili ambientali disponibili ([16]). L’entropia è un concetto fondamentale nella teoria dell’informazione: è definita come la misura della quantità di informazioni persa quando il valore di una variabile casuale non è noto ([56]). L’entropia è generalmente considerata come l’espressione del disordine di un sistema fisico o come misura della mancanza di informazioni sulle caratteristiche di un sistema fisico: maggiore è l’informazione minore è l’entropia ([44]). In MaxEnt, l’entropia misurata all’interno di una cella corrispondente ad un record di presenza dell’entità indagata dovrebbe essere bassa, mentre l’entropia misurata all’interno di una cella di presenza incerta dovrebbe essere alta ([45]).
Una caratteristica importante dell’approccio utilizzato da MaxEnt è che risulta efficace anche utilizzando campioni di piccole dimensioni, quali quelli disponibili generalmente per studi a scala di paesaggio, provenienti da atlanti faunistici o erbari e archivi storici ([42], [41], [35]). Attraverso l’utilizzo dei dati di presenza delle specie e delle variabili ambientali (continue o categoriche) per l’area di studio, viene generata una stima della probabilità di presenza di una specie che varia tra 0 e 1, dove 0 rappresenta la minima probabilità e 1 la massima probabilità di presenza.
Al fine di valutare l’efficacia della predizione del modello sono stati seguiti gli approcci tradizionali che consistono nell’utilizzo delle curve ROC (Receiver Operating Characteristic curves, [26], [69]). Le curve ROC sono rappresentazioni grafiche che valutano la performance predittiva del modello sulla base di una variabile di risposta, in questo caso la presenza/assenza della specie analizzata. Il valore dell’area al di sotto della curva (AUC) indica l’accuratezza del modello ([44]). Per predizioni completamente casuali, il valore di AUC è 0.5. Il vantaggio maggiore dell’analisi delle curve ROC è che il valore AUC rende disponibile una misura singola di accuratezza del modello, indipendentemente dai possibili valori soglia utilizzati.
Attraverso una procedura iterativa, sono state effettuate più repliche (100) per ciascuna delle quattro tipologie forestali individuate; attraverso questo metodo, il training set (set di record di presenza) utilizzato per ciascuno dei 100 modelli calcolati, viene selezionato attraverso un campionamento con sostituzione (bootstrap) di un 25% di record che vengono utilizzati come test per ogni replica ([45]).
Classificazione della copertura forestale di tipo crisp
Sono state considerate tre tecniche di classificazione di tipo crisp: (i) classificazione manuale; (ii) classificazione supervised di tipo pixel-based ; (iii) classificazione supervised di tipo object-oriented.
Al fine di ottenere un esempio di classificazione manuale è stata acquisita una mappa Corine Land Cover (terzo e quarto livello - [6]) relativa all’area di studio.
Le altre due tecniche di classificazione sono state effettuate utilizzando l’immagine satellitare Landsat ETM+ (colonna 191, riga 031, data di acquisizione Luglio 2005; risoluzione spaziale 30 m, bande 1-5) come base e gli stessi 60 punti forestali utilizzati per la creazione del modello di distribuzione MaxEnt, come training set. Inoltre, 15 punti aggiuntivi sono stati utilizzati per la classificazione delle aree non-forestali, che comprendono tutte le superfici artificiali e le aree agricole.
Nell’approccio pixel-based, l’obiettivo generale della procedura di classificazione è l’attribuzione ad una classe di appartenenza di tutti i pixel in un’immagine ([65]). Normalmente, la classificazione viene effettuata utilizzando la firma spettrale (signature) di ciascun pixel, che viene così assegnato alle varie classi del sistema di nomenclatura attraverso un algoritmo di classificazione ([33]). In questo studio, la classificazione pixel-based è stata effettuata utilizzando un algoritmo di massima verosomiglianza (maximum likelihood) disponibile nel software GIS GRASS ([38]).
Il processo di classificazione object-oriented è stato effettuato utilizzando il software eCognition ([8]). Questa tecnica di classificazione può essere suddivisa in due parti principali: (i) segmentazione multirisoluzione; e (ii) attribuzione dei tematismi. L’algoritmo di segmentazione viene definito multirisoluzione poiché aggrega in cicli successivi i pixel dell’immagine in cluster progressivamente più grandi, fino a quando le caratteristiche di scala e complessità non raggiungono i parametri impostati dall’operatore ([9]). I parametri utilizzati nella procedura di classificazione object-oriented sono, oltre le proprietà spettrali: le caratteristiche di forma e dimensione, il contesto e le informazioni tessiturali.
In questo studio le tipologie forestali entro le quali sono ricaduti i 60 punti di training, sono state selezionate per essere utilizzate come aree campione per la classificazione. Sono poi state sviluppate delle regole di classe da assegnare agli oggetti utilizzando le signature spettrali, la forma, la collocazione spaziale e le relazioni contestuali tra gli oggetti. Le regole sviluppate sono state poi utilizzate nella classificazione dell’immagine Landsat ETM+.
Al fine di testare la separabilità statistica delle classi crisp rispetto alla probabilità stimata di distribuzione delle tipologie forestali (FTPD), sono stati selezionati mille punti random all’interno dell’area di studio.
Successivamente, sono stati attribuiti i valori di FTPD ad ognuna delle 4 tipologie forestali, per ciascun punto casuale. I punti casuali sono, quindi, stati etichettati utilizzando le classi crisp di ogni dataset di copertura del suolo: CORINE Land Cover, classificazione pixel-based e classificazione object-oriented (Tab. 1). Per verificare quantitativamente la separabilità delle classi crisp, considerando ogni dataset di copertura del suolo, è stato condotto un test non-parametrico Kruskal-Wallis ([68]) utilizzando il software statistico R ([49]). L’ipotesi H0 verificata è stata che la media dei valori di FTPD fosse uguale per tutte le classe crisp analizzate. Infine, sono stati creati dei box-plot della FTPD sulle classi di ogni dataset di copertura del suolo, al fine di indagare graficamente la separabilità delle classi crisp rispetto ai valori di FTPD.
Tab. 1 - Contributi delle variabili relativi ai quattro modelli di nicchia ecologica realizzati per ciascuna tipologia forestale individuata nell’area di studio (%).
| Variabile | Boschi di leccio |
Boschi misti di querce caducifoglie |
Boschi misti di caducifoglie |
Boschi ripariali |
|---|---|---|---|---|
| ALT | 58.9 | 3.5 | 2.6 | 20.9 |
| banda 4 | 0 | 19.0 | 13.6 | 5.6 |
| banda 7 | 6.7 | 54.1 | 56.7 | 40.4 |
| P | 12.4 | 8.6 | 16.3 | 3.1 |
| PMA | 0 | 0.2 | 0.3 | 5.8 |
| RS | 1.6 | 5.1 | 4.3 | 0.3 |
| S | 11.5 | 6.1 | 2.3 | 21.3 |
| TME | 3 | 2.3 | 3.5 | 2.0 |
| TMI | 5.9 | 1.1 | 0.4 | 0.6 |
Risultati
I risultati del test di correlazione hanno permesso di ridurre il numero di variabili da utilizzare come predittori ambientali a 9: banda 4 (infrarosso vicino, 0.75 - 9.90 μm), banda 7 (infrarosso medio, 2.09 - 2.35 μm), altitudine (ALT), pendenza (P), radiazione solare (RS), temperatura minima media invernale (TMI), temperatura media massima estiva (TME), piovosità media annuale (PMA), suolo (S). Il modello MaxEnt per la predizione della distribuzione potenziale delle 4 tipologie di boschi, mostra una media alta di AUC e valori bassi di deviazione standard per le esecuzioni ripetute: 0.997 e 0.001 per il modello relativo ai Boschi di leccio, 0.957 e 0.012 per quello relativo ai Boschi misti di querce caducifoglie, 0.952 e 0.024 per i Boschi misti di caducifoglie, 0.987 e 0.004 per i Boschi ripariali. Le curve ROC medie per le quattro tipologie di boschi sono mostrate in Fig. 2. Il modello MaxEnt creato consiste in quattro mappe di probabilità di distribuzione che mostrano la probabilità di occorrenza per ciascuna tipologia forestale (Fig. 3).
Fig. 2 - Curve ROC per ognuno dei quattro modelli elaborati: Boschi di leccio (2a), Boschi misti di querce caducifoglie (2b), Boschi misti di caducifoglie (2c) e Boschi ripariali (2d).
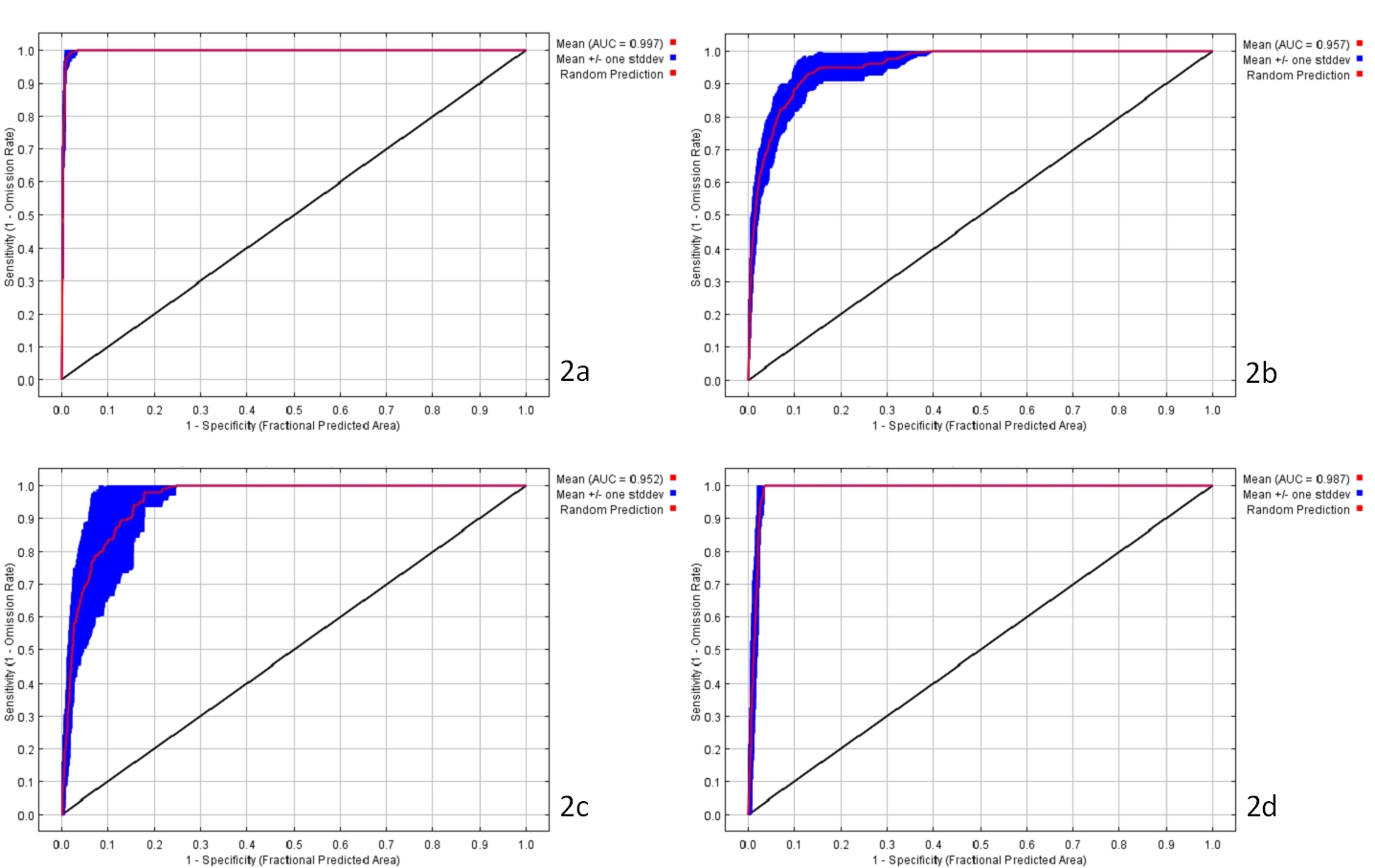
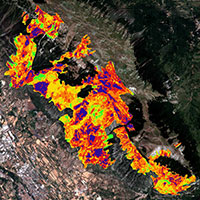
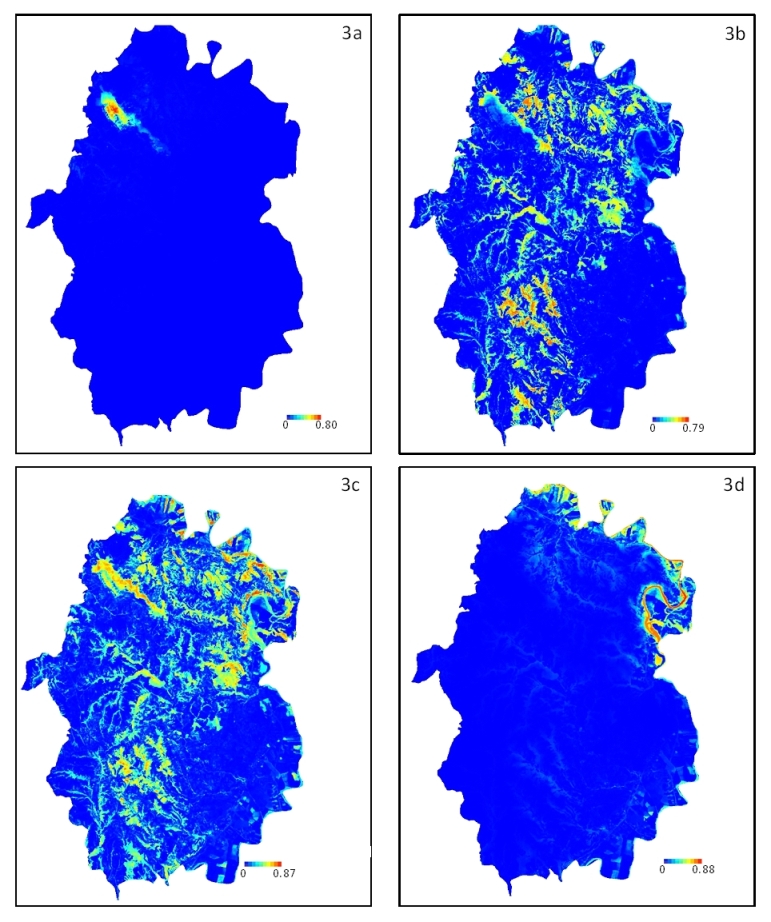
Fig. 3 - Modelli di nicchia ecologica basati sulla massima entropia (MaxEnt) per le Quattro tipologie forestali individuate: Boschi di leccio (3a), Boschi misti di querce caducifoglie (3b), Boschi misti di caducifoglie (3c) e Boschi ripariali (3d). I valori stimati di probabilità di presenza prossimi ad 1, indicano condizioni ambientali idonee per la presenza della tipologia forestale.
Il test per l’importanza delle variabili predittrici, interno a MaxEnt, mostra che l’infrarosso vicino e medio insieme alle variabili geomorfologiche rappresentano i più importanti predittori per la modellizzazione della FTPD (Tab. 1). Più in dettaglio: (i) ALT, P e S mostrano i contributi relativi più alti per il modello relativo ai Boschi di leccio; (ii) banda 4, banda 7 e P, sono i predittori più importanti per il modello relativo alla tipologia “Boschi misti di querce caducifoglie”; (iii) banda 4, P e banda 7 mostrano i contributi relativi più alti per il modello relativo alla tipologia “Boschi misti di caducifoglie”; mentre (iv) banda 4, S e ALT sono i predittori più importanti per il modello relativo ai Boschi ripariali.
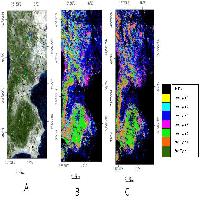
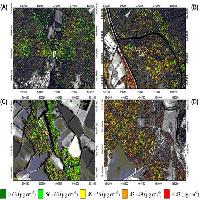
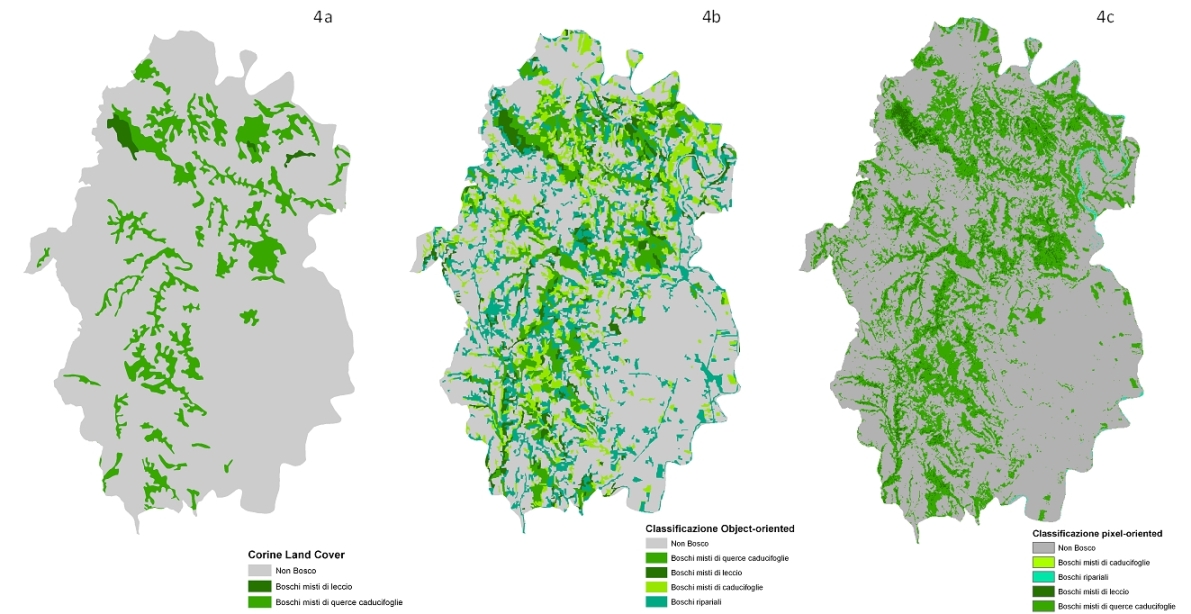
Le classificazioni pixel-based, object-oriented e la mappa CLC sono mostrate in Fig. 4. Considerando i risultati del test di Kruskal-Wallis, le quattro tipologie forestali risultano statisticamente differenti (p<0.001) per ogni tecnica di classificazione adottata rispetto ai valori di probabilità di distribuzione delle classi forestali individuate.
Fig. 4 - Le classificazioni delle coperture forestali di tipo discreto o crisp prese in considerazione in questo studio: Corine land Cover (4a), object-oriented (4b) e pixel-oriented (4c).
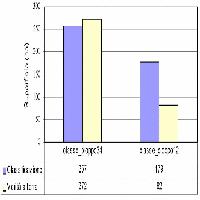
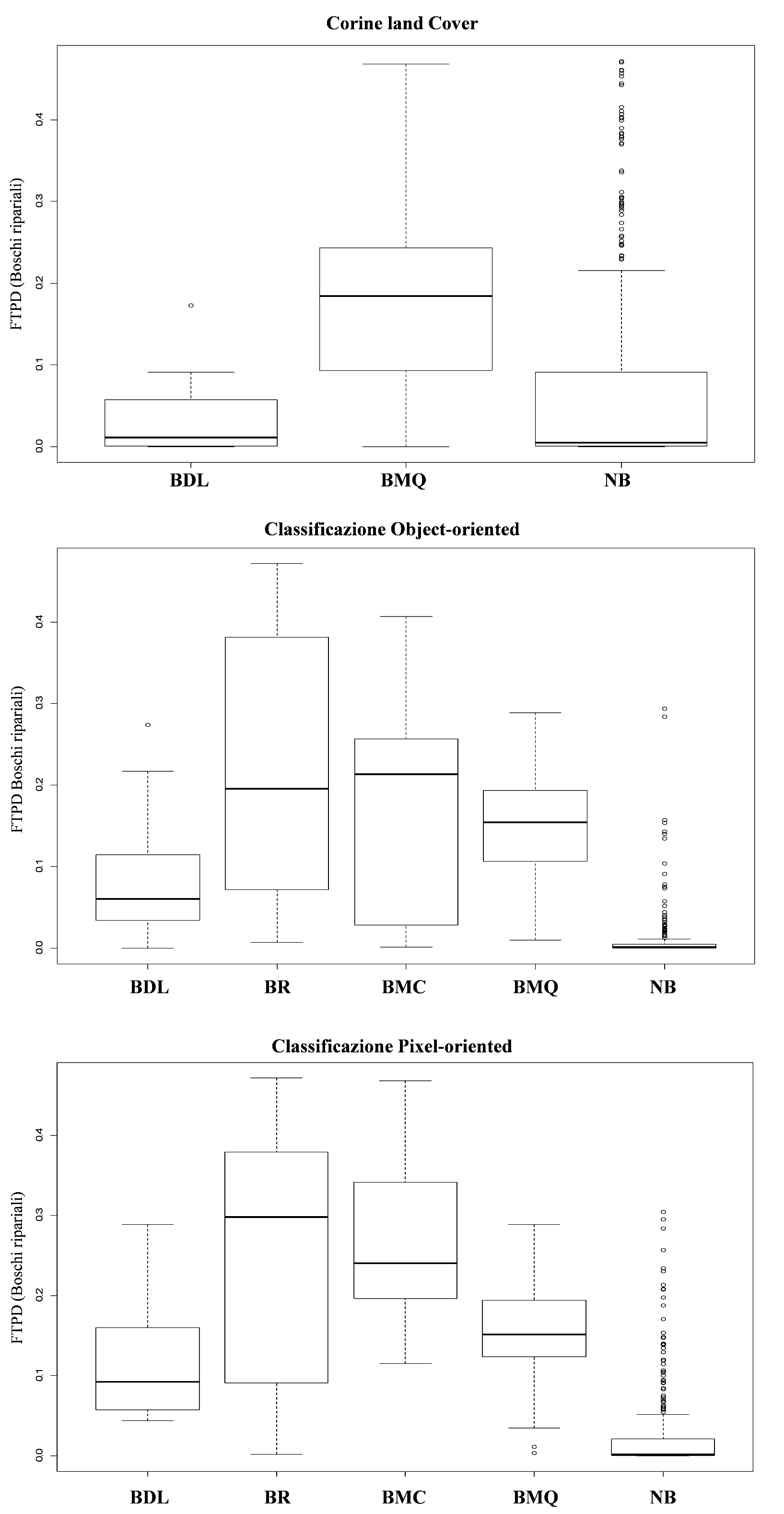
Alti valori di FTPD e un’alta distinguibilità tra le classi è stata evidenziata per i boschi di leccio per tutti e tre i tipi di classificazione considerate. Al contrario, la classe “boschi misti” generalmente mostra bassi valori di FTPD e alti valori di incertezza associati (Fig. 5, Fig. 6, Fig. 7 e Fig. 8).
Fig. 5 - Box-plot del grado di appartenenza delle classi forestali individuate da ciascuna delle tre classificazioni rispetto al probabilità di distribuzione (FTPD) della tipologia “Boschi di leccio”. (BDL): Boschi di leccio; (BMQ): Boschi misti di querce caducifoglie; (BMC): Boschi misti di caducifoglie; (BR): Boschi ripariali; (NB): Non Bosco. Il box rappresenta il 50% centrale dei dati, la parte superiore ed inferiore rispettivamente il 75° e il 25° percentile. La linea all’interno del box indica il valore mediano mentre la lunghezza delle barre rappresentano una volta e mezzo la distanza inter-quartile.
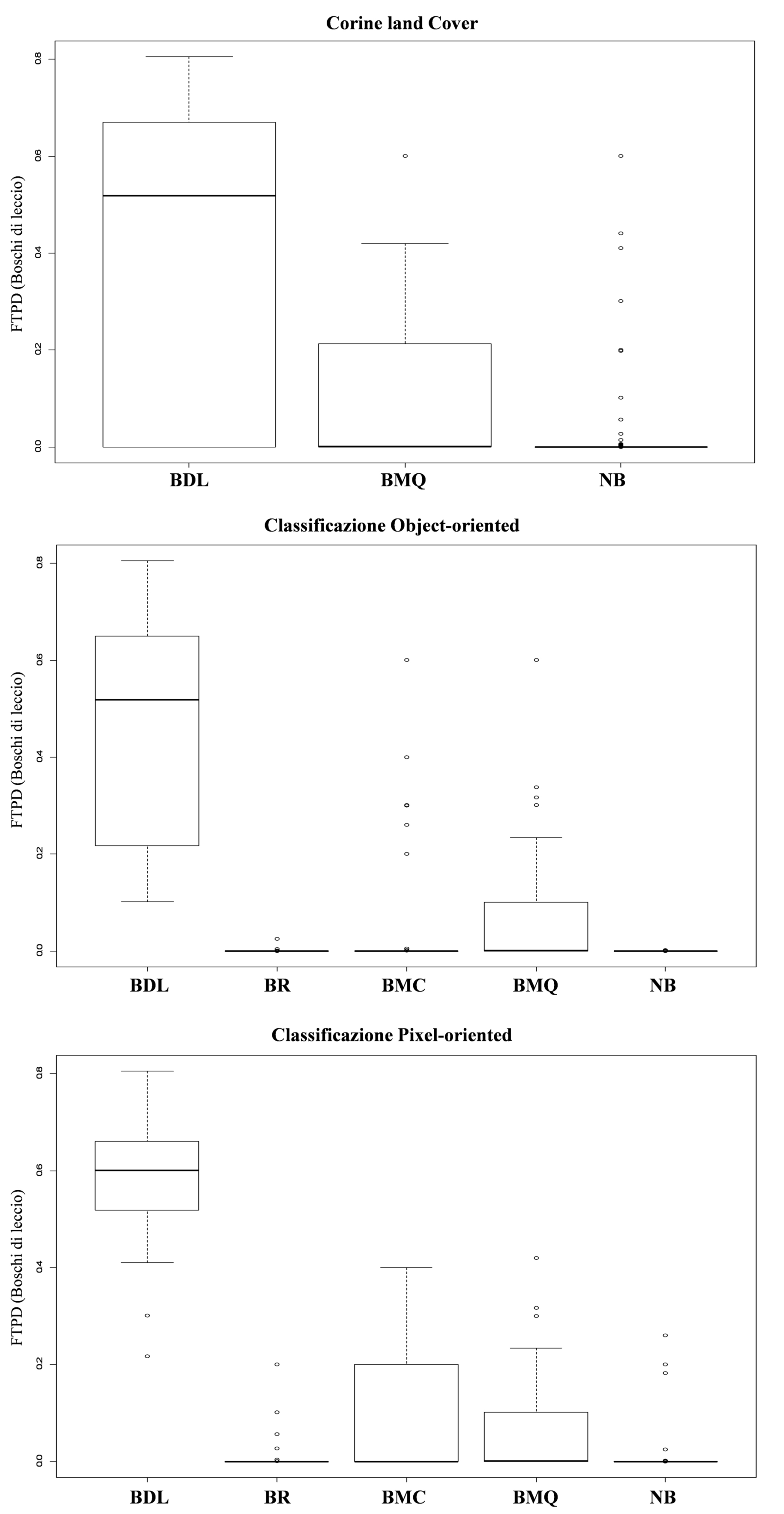
Fig. 6 - Box-plot del grado di appartenenza delle classi forestali individuate da ciascuna delle tre classificazioni rispetto al probabilità di distribuzione (FTPD) della tipologia “Boschi misti di querce caducifoglie”.
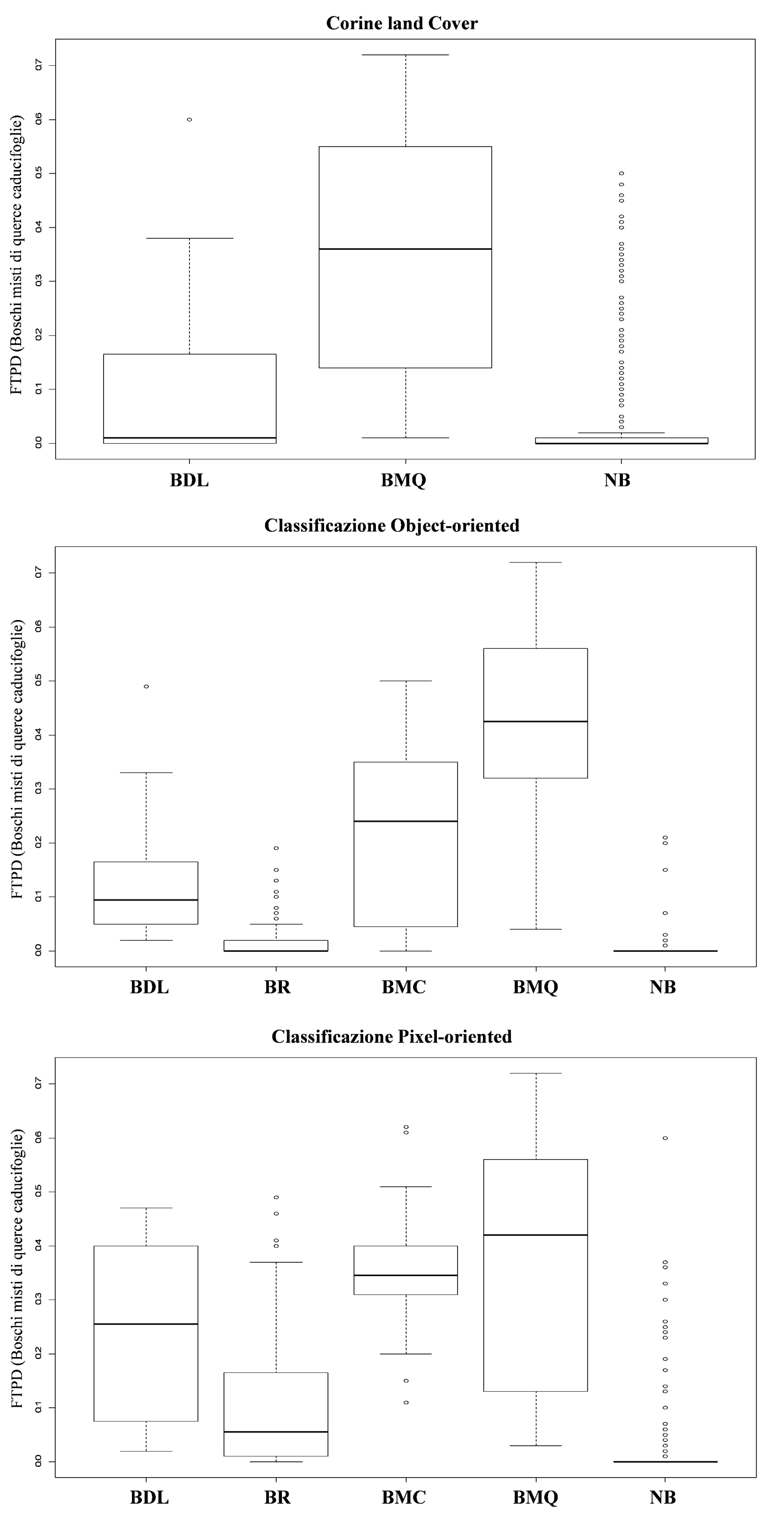
Fig. 7 - Box-plot del grado di appartenenza delle classi forestali individuate da ciascuna delle tre classificazioni rispetto al probabilità di distribuzione (FTPD) della tipologia “Boschi misti di caducifoglie”.
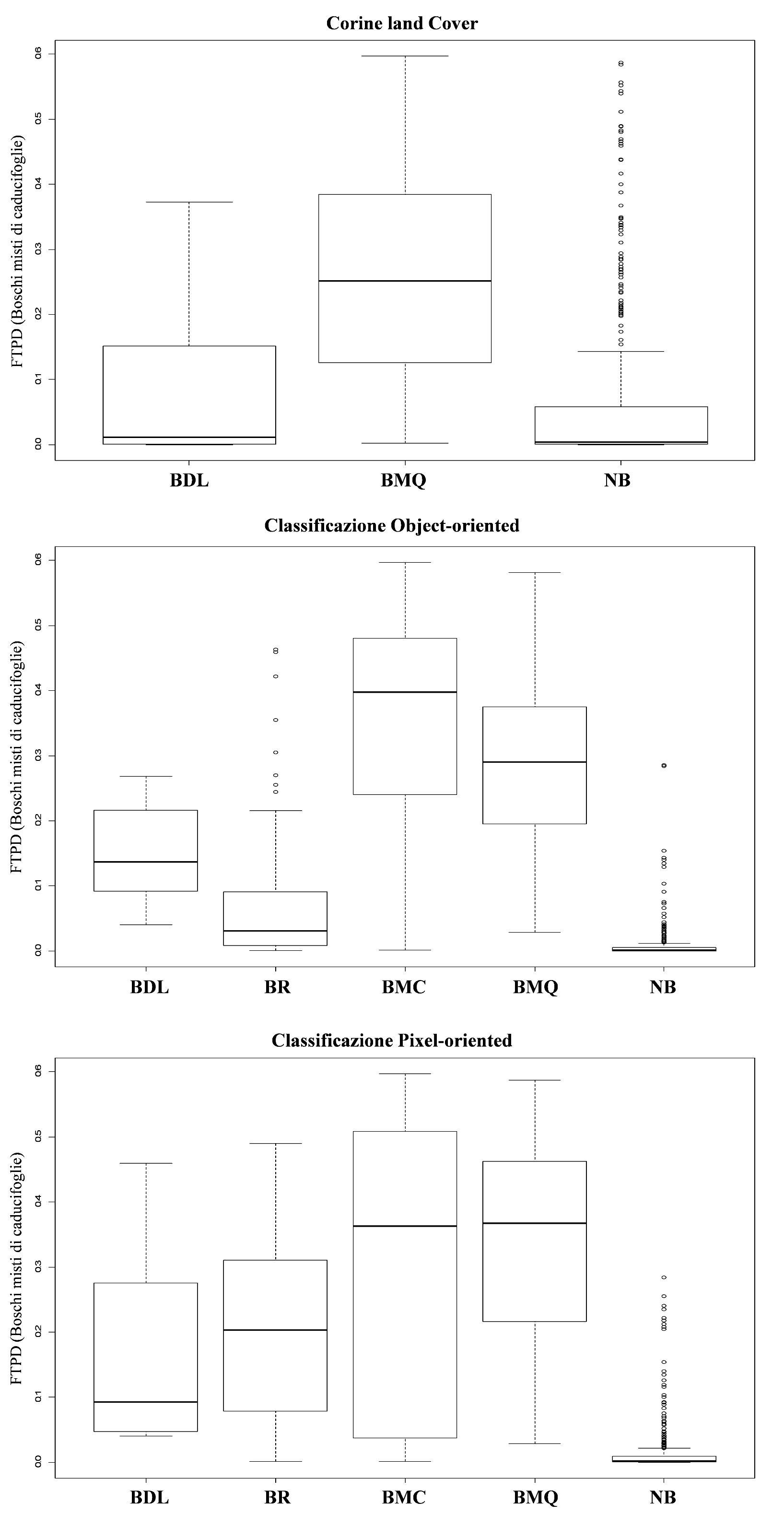
Fig. 8 - Box-plot del grado di appartenenza delle classi forestali individuate da ciascuna delle tre classificazioni rispetto al probabilità di distribuzione (FTPD) della tipologia “Boschi ripariali”.
Discussione
Dai risultati ottenuti si evidenzia l’efficacia dei modelli di distribuzione di tipo deduttivo nella realizzazione di mappe di uso o copertura del suolo di tipo continuo. Questo tipo di modelli, tenendo conto della variabilità di alcuni parametri ambientali a scala di paesaggio selezionati dall’operatore, permettono di ottenere risultati di grande rilevanza nella pianificazione di azioni di inventario forestale, permettendo ad esempio una migliore ottimizzazione dello sforzo di campionamento.
I modelli creati per le quattro tipologie boschive mostrano risultati soddisfacenti, come si evince dai valori di AUC ottenuti per le quattro tipologie forestali. Tali valori possono essere considerati delle buone misure di accuratezza poiché dati di sola presenza non possono mai produrre un AUC pari ad 1 ([34]). Si parla di dati di sola presenza poichè le porzioni di territorio adatte, ma non testate, per la presenza degli habitat analizzati, sono state trattate come assenze. In questi casi, al fine di conoscere quanto i valori di AUC siano vicini al massimo teorico è necessario conoscere in dettaglio il livello di specializzazione della nicchia ecologica delle specie dominanti, e quindi caratterizzanti l’habitat forestale. Infatti, una nicchia ecologica ampia corrisponde generalmente a bassi valori di AUC ([44]).Di conseguenza si spiega perché i valori di AUC per i boschi di leccio, che rappresentano la tipologia di bosco che occupa la nicchia ecologia meglio definita nell’aria studiata, sono mediamente più alti di quelli assunti dalle classi forestali miste, caratterizzate da un’alta eterogeneità specifica e con presenza di diverse specie con abbondanza relativa simile ([10]).
Analizzando i contributi ai modelli di distribuzione delle variabili predittrici, si nota come l’informazione spettrale risulta la variabile più importante nella caratterizzazione delle diverse tipologie forestali considerate. Si può, inoltre, notare che altre variabili risultano importanti per caratterizzare e, quindi, meglio diversificare la distribuzione degli habitat forestali; tra queste la variabile altitudinale è quella che fornisce uno dei più alti contributi alla costruzione del modello MaxEnt. I boschi di leccio e i boschi ripariali sono due tipologie forestali fortemente localizzate, da un punto di vista geografico, nell’area di studio ([2]): i primi sono situati solamente sull’unico rilievo presente nell’area studiata, mentre, i secondi si trovano localizzati prevalentemente nella valle del Tevere, l’area con la più bassa altitudine media. Le altre variabili geomorfologiche, come pendenza e radiazione solare, sono tra le variabili più importanti nella stima della probabilità di distribuzione delle classi forestali miste. Questa tipologia forestale spesso è rappresentata da remnants generalmente situate nei versanti ad alta pendenza nell’area collinare o al margine della pianura a colline ([20]). Le variabili climatiche, come ci si poteva attendere data l’estensione limitata dell’area di studio e la distanza relativamente alta che separa le centraline di rilevamento meteorologico, non forniscono un contributo determinante nella creazione dei modelli. Nonostante l’approccio proposto sia caratterizzato da un’impronta essenzialmente metodologica, è necessario prendere in considerazione il ruolo potenziale che le variabili climatiche possono avere nella realizzazione di modelli di distribuzione di tipologie di copertura del suolo naturali o semi-naturali in aree più estese e morfologicamente complesse di quella presa in esame. Come sottolineato da alcuni studi (e.g., [62]), in aree trasformate per millenni dall’azione dell’uomo, come la maggior parte delle aree del mediterraneo, il potere predittivo di modelli basati sulle variabili climatiche ed ecologiche può risultare ridimensionato a causa della maggior rilevanza che possono assumere il disturbo di origine antropica e la struttura paesaggistica risultante dai cambiamenti storici di uso del suolo. Per questo, le variabili considerate nel modello proposto e i relativi contributi non possono essere analizzati tramite un approccio esclusivamente ecologico, in quanto spesso tali variabili rappresentano una maschera di processi di trasformazione del paesaggio da parte dell’uomo difficili da misurare tramite indici sintetici. Di conseguenza, le variabili inserite nei modelli devono essere considerate essenzialmente come strati informativi geografici utili ai fini di una classificazione di tipo continuo basata sul principio della massima entropia, piuttosto che come variabili ecologiche interpretabili nell’ambito di modelli di distribuzione potenziale delle singole specie o habitat.
Appare evidente come approcci di tipo soft o fuzzy e la possibilità di includere variabili ambientali come predittori nel processo di modellizzazione, in aggiunta all’informazione spettrale, permette di migliorare l’accuratezza delle classificazioni di uso o copertura del suolo ([61], [50], [19]). Come conseguenza gli approcci di classificazione comuni di tipo crisp, sono limitati dall’impossibilità di incorporare nella procedura di classificazione informazioni contestuali o tipologiche relative alle variazioni continue e graduali delle caratteristiche ambientali ([12], [30]).
L’utilizzo dei modelli ottenuti tramite MaxEnt e validati tramite l’accordo con i dati sul campo, per stimare l’incertezza associata alle classificazioni che seguono una logica di tipo booleano, può rappresentare un test a supporto di quanto affermato nel paragrafo precedente. I tre classificatori qui considerati hanno prodotto risultati che mostrano una differenza statisticamente significativa tra le classi di copertura del suolo nei valori di idoneità potenziale del processo di modellizzazione (FTPD). Tuttavia, i valori di FTPD variano fortemente al variare della tipologia boschiva studiata. Considerando il CORINE Land Cover, si nota come le classi “Boschi misti di caducifoglie” e “Boschi ripariali” non sono state classificate all’interno dell’area di studio. La sottostima della presenza di queste due classi è probabilmente dovuta non solo ad una questione metodologica, e quindi legata alla soggettività nell’assegnazione delle classi, ma anche alla minima unità mappabile, pari a 25 ha ([6]). Infatti una unità minima mappabile così grossolana non rende possibile l’identificazione di tipologie forestali rappresentate per lo più da patch piccole e frammentate, come quelle che caratterizzano, nell’area di studio, le tipologie “Boschi misti caducifogli” e “Boschi ripariali”. Come atteso, per il CLC e per le altre due classificazioni utilizzate è stata riscontrata una maggiore separabilità tra le aree non forestali e quelle forestali e tra i Boschi di leccio e le altre tipologie forestali considerate. Un altro risultato interessante consiste nel fatto che, comparando i due dataset crisp supervised, la classificazione pixel-based per i Boschi di leccio presenta più alti valori di FTPD rispetto alla classificazione object-oriented. Questo è dovuto, probabilmente, ai differenti metodi di classificazione. La classificazione pixel-based è ideata per classificare aree spazialmente omogenee e ben definite, come quelle occupate dai Boschi di leccio nell’area di studio ([57], [21]). In particolare, questo metodo di classificazione permette di identificare piccoli frammenti di vegetazione a sclerofille o gap presenti all’interno dei Boschi di leccio, caratterizzati dalla presenza di caducifoglie adattate a condizioni ecologiche particolari (suolo, esposizione, ecc.). Per quanto riguarda le classi miste, la classificazione object-oriented mostra valori di FTPD relativamente alti rispetto alla classificazione pixel-oriented e il CLC, e una distinguibilità più alta delle classi Boschi di misti di querce caducifoglie e Boschi misti di caducifoglie rispetto alle altre classi. Questo è dovuto probabilmente non solo alla estrema variabilità dello strato arboreo di queste classi, ma anche alla struttura spaziale delle patch. Infatti, l’approccio object-oriented dovrebbe consentire di distinguere le classi miste poiché può raggruppare i pixel in oggetti attraverso informazioni spaziali e di tessitura ([9]). La tessitura delle foreste nell’area di studio è significativamente influenzata dai processi di frammentazione che relegano spesso le superfici forestali in piccole valli fluviali o in aree ad elevata pendenza.
I valori di FTPD della classe riferibile alla vegetazione ripariale (dominata da Populus spp. e Salix spp.) sono più alti per la classificazione pixel-based piuttosto che per quella object-oriented. Questo è probabilmente spiegabile dalla piccola estensione delle fasce boscate ripariali e dalla loro estrema variabilità tessiturale ([1]). Ciò potrebbe rendere l’informazione spettrale l’unico elemento efficace per la distinzione di questa classe dagli oggetti adiacenti.
In conclusione, prescindendo dal metodo di classificazione utilizzato, le classi boschive di tipo crisp mostrano sempre una grande variabilità interna (incertezza). Tale grado di incertezza può essere spiegato principalmente tramite la commistione intrinseca che caratterizza le classi di copertura forestali naturali o semi-naturali ([58]). I possibili problemi associati ad una risoluzione spaziale differente ([29]), sono stati presi in considerazione in questo studio utilizzando il medesimo dataset (Landsat ETM +) come base per le classificazioni crisp. Il problema legato alla scala e all’unità minima mappata, comunque, deve essere affrontato, in particolare per quanto riguarda il Corine Land Cover. Come sottolineato durante questo studio, esiste una differenza tra la rappresentazione degli oggetti spaziali fornita dal Corine Land Cover e le entità reali presenti sulla superficie rappresentata, questo perché un’entità spaziale o un fenomeno ecologico possono non essere osservati se si sceglie una scala spaziale errata ([60]). Questo è avvenuto nel caso dei Boschi misti di caducifoglie e dei Boschi ripariali. Infatti, come ci si poteva attendere, una mappa crisp con unità mappabile minima di 25 ha non è in grado di soddisfare la risoluzione tematica dei soggetti rappresentati ([37]); classi crisp maggiormente dettagliate potrebbero essere rappresentate solo con risoluzione spaziale più alta e con la classificazione di oggetti spaziali più piccoli (p. es., siepi), mentre è atteso un più alto grado di commistione spettrale e incertezza tematica interna quando gli oggetti (sia poligoni che pixel) diventano più grandi ([3]).
Conclusioni
In questo lavoro, l’applicazione di un modello basato sul principio di massima entropia (MaxEnt), generalmente utilizzato per creare modelli di distribuzione di specie e/o habitat, è stata testata per la classificazione soft di alcune tipologie di copertura forestale del suolo (“Boschi di leccio”, “Boschi misti di querce caducifoglie”, “Boschi misti di caducifoglie”, “Boschi ripariali”).
In questo contesto è necessario sottolineare la sperimentalità dell’approccio basato sull’utilizzo di un modello di nicchia ecologica all’interno di un processo di classificazione del territorio. In particolare la scelta delle tipologie forestali da modellizzare, essendo esse entità complesse e non semplici come le singole specie, può rappresentare una sorgente di errori nel processo di modellizzazione. Al fine di ridurre il più possibile la soggettività nella scelta delle tipologie vegetazionali da indagare, oltre ad uniformare la classificazione prodotta con le cartografie tematiche attualmente presenti, è stato scelto di basarsi su un sistema di nomenclatura standard come il Corine Land Cover. Questo ha permesso anche il confronto tramite validazione successiva del modello soft-based con le classificazione di tipo crisp. Infatti, l’utilizzo delle mappe risultanti come dati di validazione per le classificazioni di tipo crisp, ha permesso di evidenziare come le classificazioni crisp, utilizzate comunemente nella ricerca e nella pianificazione del territorio, presentano alcune problematiche, connesse ad un alto grado di variabilità interna alle classi create. Quindi, come sottolineato più volte da altri studi ([55], [51], [52]), è necessario tenere in considerazione le problematiche che possono derivare da una visione crisp delle entità ecologiche mappate. Gli habitat, in quanto sistemi naturali, sono strutturalmente complessi e variano gradualmente e continuamente entro il paesaggio in conseguenza delle variazioni continue e graduali delle caratteristiche ambientali. Infine occorre sottolineare come l’approccio di classificazione proposto necessita di una elevata quantità di informazioni disponibili ad una scala adeguata a quella dell’analisi eseguita ed una attenta selezione delle stesse in base alla loro potenziale importanza nella determinazione dei pattern di distribuzione delle tipologie di copertura del suolo.
References
Google Scholar
Google Scholar
Online | Google Scholar
CrossRef | Google Scholar
CrossRef | Google Scholar
Google Scholar
Google Scholar
Google Scholar
CrossRef | Google Scholar
Google Scholar
CrossRef | Google Scholar
Online | Google Scholar
CrossRef | Google Scholar
CrossRef | Google Scholar
CrossRef | Google Scholar
CrossRef | Google Scholar
CrossRef | Google Scholar
Online | Google Scholar
CrossRef | Google Scholar
CrossRef | Google Scholar
Google Scholar
CrossRef | Google Scholar
Online | Google Scholar
CrossRef | Google Scholar
CrossRef | Google Scholar
Google Scholar
Google Scholar
CrossRef | Google Scholar
CrossRef | Google Scholar
CrossRef | Google Scholar
Google Scholar
Google Scholar
Google Scholar
CrossRef | Google Scholar
Google Scholar
CrossRef | Google Scholar
CrossRef | Google Scholar
Google Scholar
CrossRef | Google Scholar
Online | Google Scholar
CrossRef | Google Scholar
CrossRef | Google Scholar
Google Scholar
CrossRef | Google Scholar
CrossRef | Google Scholar
CrossRef | Google Scholar
Google Scholar
Online | Google Scholar
Google Scholar
CrossRef | Google Scholar
CrossRef | Google Scholar
CrossRef | Google Scholar
Online | Google Scholar
CrossRef | Google Scholar
CrossRef | Google Scholar
Google Scholar
Google Scholar
CrossRef | Google Scholar
CrossRef | Google Scholar
CrossRef | Google Scholar
CrossRef | Google Scholar
CrossRef | Google Scholar
Google Scholar
CrossRef | Google Scholar
Google Scholar
CrossRef | Google Scholar
CrossRef | Google Scholar
Google Scholar
Google Scholar